Pythonの型ヒント(type hints)は、コードの可読性や静的解析の精度を高めるための重要な仕組みとして広く知られています。
しかし一方で、「本当に必要なのか?」という疑問を抱く開発者も少なくありません。
特に動的型付け言語であるPythonの特性を踏まえると、型ヒントの導入が必ずしも最適とは限らないという見方も十分に合理的です。
本記事では、Pythonにおける型ヒントの役割を踏まえつつ、あえて「不要派」の立場からその主張を論理的に整理します。
私自身、コンピューターサイエンスの学位を持ち、日々コードの設計やレビューに携わる中で、型ヒントの有用性と同時にその限界も実感してきました。
型ヒントは確かに、以下のようなメリットを持ちます。
- 静的解析ツールによるバグの早期発見
- IDEによる補完精度の向上
- チーム開発における意図の明示
しかし、それと同時に無視できないデメリットや運用コストも存在します。
例えば、型定義の記述が増えることによる可読性の低下や、型と実装の乖離が発生するリスクなどです。
本記事では、こうしたトレードオフを踏まえた上で、型ヒントが不要だと主張される3つの合理的な理由について、実務的な視点から解説していきます。
Python開発において型ヒントをどのように扱うべきか迷っている方にとって、判断材料となる内容を提供します。
Pythonの型ヒントとは?基礎とPythonの動的型付けの関係
Pythonの型ヒントは、変数や関数の引数、戻り値に対して「期待される型」を明示的に記述する仕組みである。
これはPythonの実行時の挙動に直接影響を与えるものではなく、主に開発者や静的解析ツールに対して意味を持つ補助的な情報として機能する。
Pythonは本来、動的型付け言語であり、変数の型は実行時に決定される。
この性質により、同一の変数に異なる型の値を代入することも可能であり、柔軟で記述量の少ないコードを書くことができる。
一方で、この柔軟性は大規模な開発やチーム開発においては、可読性や保守性の観点で課題を生むことがある。
そこで導入されたのが型ヒントである。
型ヒントを用いることで、コード上に明示的な型情報を付与し、読み手がその関数や変数の意図をより正確に理解できるようになる。
また、IDEや静的解析ツールはこの情報を利用して補完機能を強化したり、潜在的な型エラーを検出したりすることが可能になる。
Pythonにおける型ヒントは、PEP 484で正式に仕様として定義されている。
例えば、関数の引数や戻り値に対して型を指定することで、その関数がどのようなデータを受け取り、何を返すのかが明確になる。
このような記述は実行時には無視されるため、あくまで開発支援のためのメタ情報として扱われる点が重要である。
ここで重要なのは、Pythonの動的型付けとの関係である。
動的型付けとは、変数の型がコンパイル時ではなく実行時に決定される仕組みを指す。
これに対して静的型付けでは、変数の型は事前に固定され、型の整合性がコンパイル時に検証される。
Pythonは動的型付けを採用しているため、型の制約に縛られず柔軟にコードを書くことができるが、その代償として型に起因するエラーが実行時まで検出されないという特性がある。
型ヒントは、この動的型付けの上に静的型付け的な要素を部分的に導入する仕組みと捉えることができる。
すなわち、実行時の柔軟性を維持しつつ、開発時には型情報を活用して安全性と可読性を高めるという折衷的なアプローチである。
このため、型ヒントは言語仕様として強制されるものではなく、あくまでオプショナルな機能として設計されている。
さらに、型ヒントの価値はツールとの組み合わせによって大きく変わる。
例えば、mypyのような静的型チェッカーを用いることで、型ヒントに基づいた厳密な型チェックを事前に行うことができる。
また、PyrightやIDEの補完機能は、型ヒントを利用することで開発体験を大幅に向上させる。
これにより、動的型付けの柔軟性を維持しながらも、静的型付けに近い恩恵を受けることが可能となる。
しかしながら、この仕組みは必ずしもすべての開発者にとって必要不可欠ではない。
小規模なスクリプトや短期間で書き捨てるコードにおいては、型ヒントを導入するコストがメリットを上回る場合もある。
逆に、長期的に保守される大規模なシステムでは、型ヒントが品質向上に寄与する場面が多い。
このように、型ヒントの必要性はプロジェクトの性質や開発スタイルによって大きく変わる。
結論として、Pythonの型ヒントは動的型付けという言語の本質を損なうことなく、静的解析や開発支援を強化するための補助的な機構である。
その導入は強制されるものではなく、あくまで開発者の判断に委ねられている。
この柔軟性こそが、Pythonにおける型ヒントの本質的な特徴であると言える。
型ヒントと静的型付けの違いを比較して理解する
型ヒントと静的型付けは、一見すると似た概念に見えるが、その本質と役割は明確に異なる。
両者の違いを正確に理解することは、Pythonにおける型システムの位置づけを把握する上で重要である。
まず静的型付けについて考える。
静的型付けとは、変数の型がコンパイル時に決定され、その後はその型に従って厳密に処理が行われる仕組みである。
この仕組みを採用する言語では、型の不一致があるとコンパイル時にエラーとして検出されるため、実行前に多くの潜在的な不具合を排除できる。
代表的な例としては、JavaやC++、TypeScriptなどが挙げられる。
これに対して、Pythonは動的型付けを採用しており、変数の型は実行時に決定される。
そのため、同一の変数に異なる型の値を代入することが可能であり、柔軟性の高いプログラミングが実現される。
ただし、この柔軟性は型に関連するエラーが実行時まで発見されないというトレードオフを伴う。
ここで登場するのが型ヒントである。
型ヒントは、Pythonの動的型付けの上に「型情報を付加する」という形で導入された仕組みであり、言語の実行モデルそのものを変えるものではない。
つまり、型ヒントは静的型付けのように型チェックを強制するものではなく、あくまで補助的な情報として扱われる。
この違いを明確にするために、両者の性質を比較すると理解が深まる。
静的型付けは、言語仕様として型の整合性を厳密に管理する。
一方で型ヒントは、あくまで開発者が任意に付与する注釈であり、実行時の挙動には影響を与えない。
このため、型ヒントが存在していても、Pythonのインタプリタはそれを無視してコードを実行する。
ただし、型ヒントは静的解析ツールと組み合わせることで、静的型付けに近い効果を得ることができる。
例えば、mypyのようなツールは型ヒントを解釈し、型の整合性を事前に検証する。
これにより、開発者は実行前に型に関する問題を検出できるようになる。
この関係性は次のように整理できる。
- 静的型付けは言語レベルで型を強制する仕組みである
- 型ヒントは実行時に影響を与えない注釈である
- 型ヒントは外部ツールと組み合わせることで静的解析を可能にする
この違いを理解することで、型ヒントの位置づけがより明確になる。
すなわち、型ヒントは静的型付けそのものではなく、静的型付け的な恩恵を後付けで得るための手段である。
さらに重要なのは、設計思想の違いである。
静的型付けは、型安全性を言語レベルで保証することを目的としている。
一方で型ヒントは、柔軟性を維持しながら必要に応じて型情報を付加するという、より現実的なアプローチを採用している。
この違いは、開発スタイルやプロジェクトの性質に大きく影響を与える。
例えば、厳密な型安全性が求められる大規模なシステムでは静的型付けが有効である。
一方で、迅速なプロトタイピングや柔軟なスクリプト開発では、動的型付けと型ヒントの組み合わせが適している場合が多い。
このように、両者は対立する概念というよりも、異なる設計思想に基づく選択肢と捉えるべきである。
最終的に、型ヒントと静的型付けの関係は、「強制されるかどうか」という一点に集約される。
静的型付けは強制的な仕組みであり、型ヒントは任意の補助情報である。
この違いを正しく理解することで、Pythonにおける型システムの本質をより深く理解できるようになる。
Pythonに型ヒントが不要とされる理由①:動的型付けの柔軟性
Pythonにおいて型ヒントが不要と主張される理由の一つとして、動的型付けがもたらす本質的な柔軟性が挙げられる。
Pythonは設計段階から動的型付けを前提としており、変数や関数の型は実行時に決定される。
この特性により、開発者は型の制約に縛られることなく、直感的かつ迅速にコードを記述することが可能となる。
動的型付けの利点は、コードの自由度が高い点にある。
例えば、同一の関数に対して異なる型の引数を渡すことができるため、汎用性の高いコードを柔軟に設計できる。
これは特に、プロトタイピングや探索的な開発において大きな利点となる。
厳密な型定義が要求される静的型付け言語では、このような柔軟な書き方は制約されることが多い。
さらに、動的型付けはコードの記述量を削減する効果も持つ。
型を明示的に記述する必要がないため、関数や変数の定義が簡潔になり、全体として読みやすいコードを維持しやすくなる。
この点は、小規模なスクリプトや短期間での開発において特に有効である。
開発の初期段階では仕様が流動的であることが多く、頻繁な変更に対応する必要があるため、厳密な型定義はかえって開発速度を低下させる可能性がある。
このような背景から、型ヒントを導入しない選択は合理的であると考えられる場合がある。
型ヒントを導入すると、コードに型情報を付与するための追加の記述が必要になるだけでなく、型の整合性を維持するための設計上の制約も増える。
その結果、柔軟性が損なわれる可能性がある。
動的型付けのもう一つの重要な側面は、設計の抽象度を高めやすい点にある。
型に依存しない設計が可能であるため、具体的なデータ構造に縛られず、より抽象的なロジックを構築することができる。
これにより、再利用性の高いコードや、拡張性のある設計が実現しやすくなる。
一方で、動的型付けはランタイムエラーのリスクを伴う。
型の不一致によるエラーはコンパイル時ではなく実行時に発生するため、問題の検出が遅れる可能性がある。
この点に対して、型ヒントは静的解析ツールと組み合わせることで一定の補助を提供するが、それでも完全な保証を与えるものではない。
しかし、重要なのはこのトレードオフの捉え方である。
型ヒントによって得られる安全性と、動的型付けによる柔軟性は、常に両立するとは限らない。
特に、開発の初期段階や試行錯誤が求められる場面では、柔軟性の方が優先されるケースが多い。
この場合、型ヒントは必須ではなく、むしろ制約として機能する可能性がある。
また、Pythonのコミュニティにおいても、型ヒントの利用は必須ではなく、あくまでオプションとして位置づけられている。
この設計思想は、Pythonが「読みやすく、書きやすい言語」であることを重視している点と一致している。
動的型付けの柔軟性は、その理念を支える重要な要素である。
したがって、型ヒントが不要とされる背景には、単なる好みではなく、言語設計に根ざした合理的な理由が存在する。
動的型付けの柔軟性は、開発速度、コードの簡潔性、設計の自由度といった複数の観点において価値を持ち、これらを最大限に活かすためには、型ヒントをあえて導入しないという選択も十分に合理的であると言える。
Pythonに型ヒントが不要とされる理由②:記述コストと可読性の低下
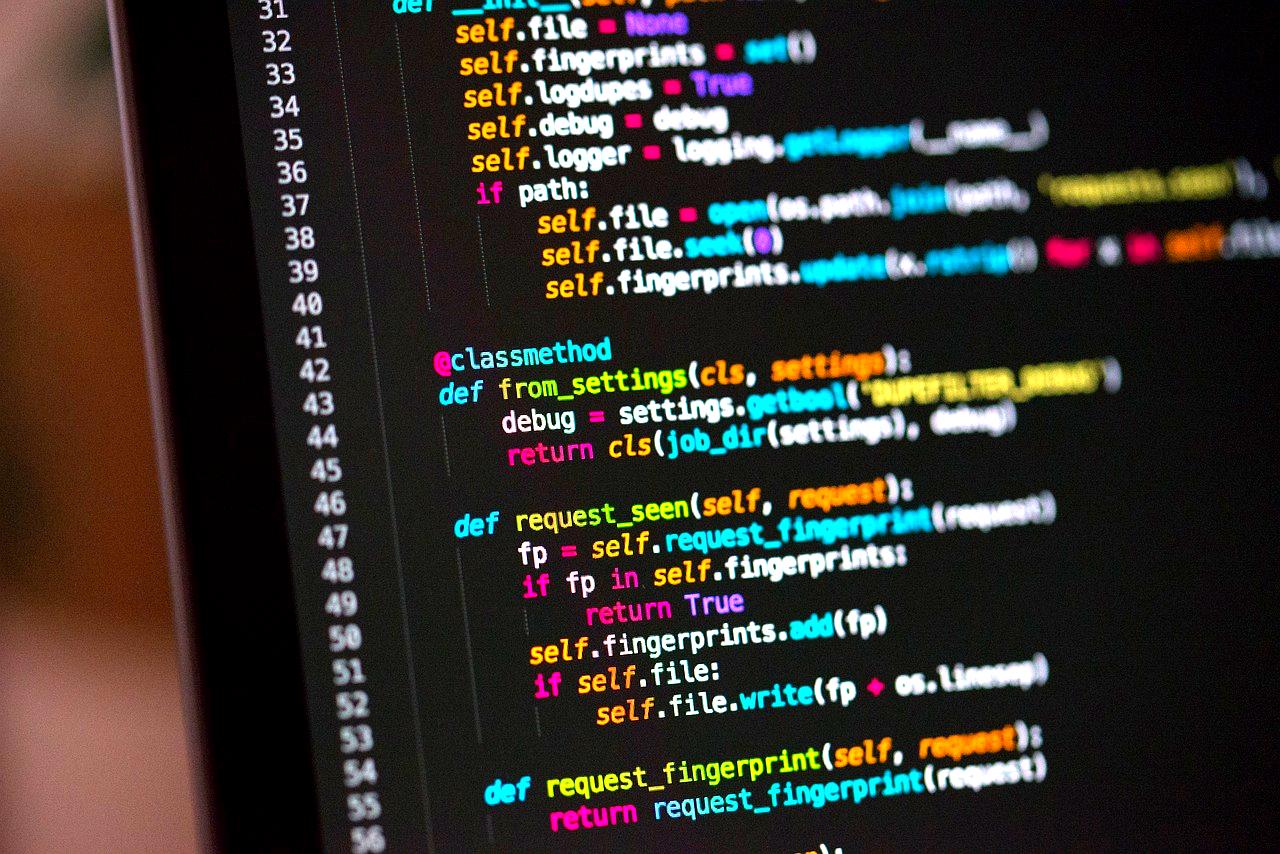
Pythonにおいて型ヒントが不要とされる理由の一つに、記述コストの増加と、それに伴う可読性の低下がある。
型ヒントはコードの意図を明確にするという利点を持つ一方で、すべての変数や関数に対して型を明示的に記述することは、開発者にとって追加の負担となる。
まず記述コストの観点から考えると、型ヒントを導入することでコードの行数が増加する傾向にある。
単純な関数であっても、引数と戻り値に対して型を付与する必要があり、場合によってはジェネリクスや複雑な型アノテーションを用いることになる。
このような記述は、コードの意図を明確にする一方で、実装そのものよりも型の記述に時間を費やす結果を招くことがある。
特に、開発初期の段階や試作的なコードにおいては、このコストは無視できない。
仕様が頻繁に変更される状況では、型定義もそれに追従して修正する必要があり、変更のたびに複数箇所を更新しなければならないケースも発生する。
このような状況では、型ヒントは生産性を低下させる要因となり得る。
次に可読性の観点である。
型ヒントは一見するとコードの理解を助けるように見えるが、過度に詳細な型定義はかえって可読性を損なう場合がある。
特に、複雑なネスト構造や長いジェネリック型を使用した場合、コードの本質的なロジックよりも型定義の方が目立ってしまうことがある。
このようなコードは、読み手にとって認知負荷が高くなり、理解に時間を要する。
また、Pythonの魅力の一つは、その簡潔さにある。
関数や変数を直感的に記述できることが、Pythonが広く利用されている理由の一つである。
しかし、型ヒントを多用することで、コードは次第に冗長になり、他の静的型付け言語に近い記述スタイルへと変化していく。
この変化は、Python本来の「シンプルで読みやすい」という哲学と相反する可能性がある。
さらに、チーム開発における可読性の問題も考慮する必要がある。
型ヒントに対する理解度は開発者によって異なるため、全員が同じレベルで型定義を解釈できるとは限らない。
特に高度な型システムを活用した場合、その意味を正確に理解するには一定の学習コストが必要になる。
このため、型ヒントが逆にコミュニケーションの障壁となる可能性もある。
一方で、型ヒントが可読性を向上させるケースも存在する。
関数のインターフェースが明確になり、外部から見たときの仕様理解が容易になる点は確かにメリットである。
しかし、この利点は必ずしもすべてのコードにおいて必要とされるものではない。
特に内部的なロジックや短いスクリプトでは、型ヒントを省略することでコードの見通しが良くなる場合も多い。
このように、型ヒントの導入は単純な善悪の問題ではなく、記述コストと可読性のトレードオフとして捉えるべきである。
コードの品質を高めるために型ヒントを活用することは有効であるが、その一方で過剰な使用は開発効率や可読性を損なう可能性がある。
結論として、型ヒントは有用なツールであるものの、その導入には明確なコストが伴う。
このコストがメリットを上回る場合、あえて型ヒントを使用しないという選択は合理的であり、特にシンプルさと柔軟性を重視するPythonの思想においては、十分に正当化される判断であると言える。
Pythonに型ヒントが不要とされる理由③:型と実装の乖離リスク
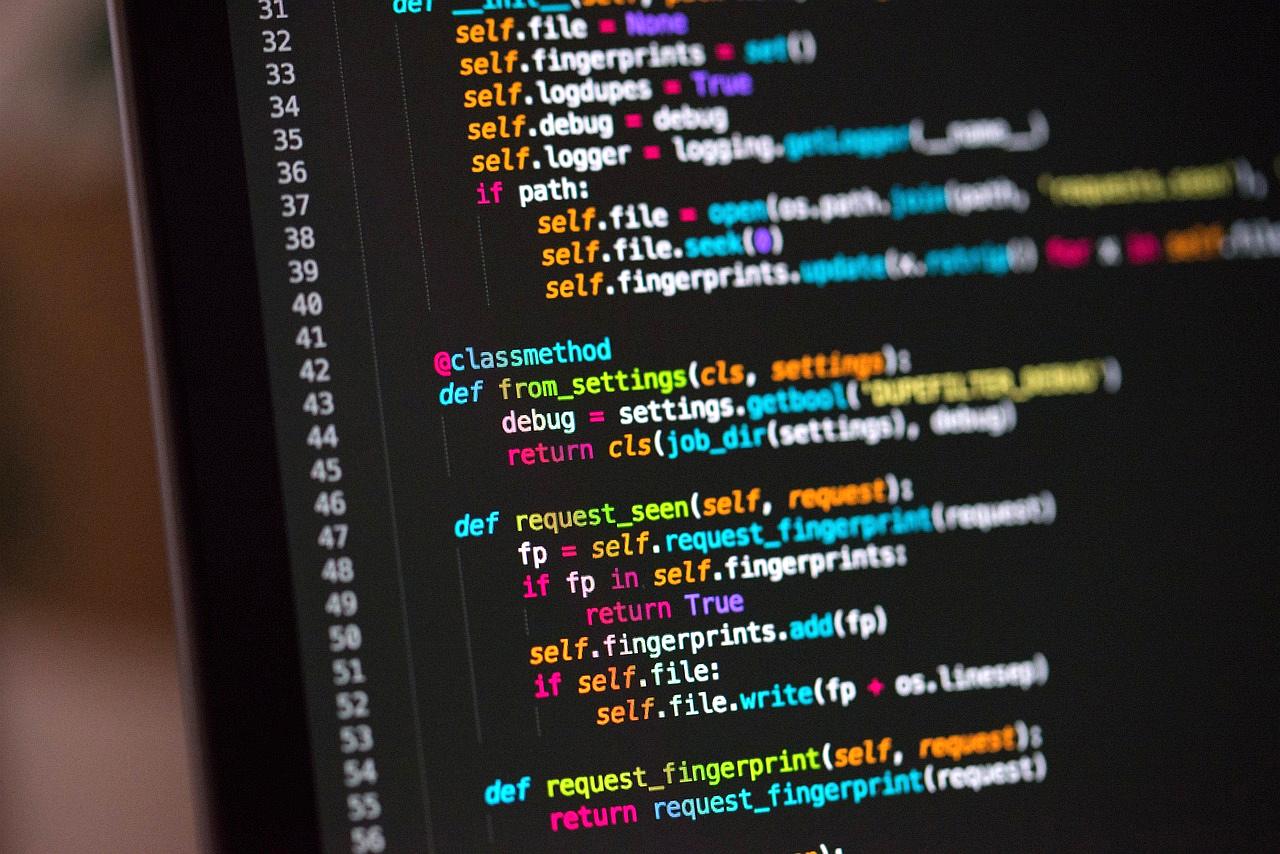
Pythonにおいて型ヒントが不要とされる理由の三つ目として、型定義と実際の実装が乖離するリスクが挙げられる。
型ヒントはコードの意図を明確にするための有効な手段である一方で、その定義が実装と常に一致していることを保証する仕組みではない。
この点が、運用上の大きな課題となる場合がある。
型ヒントはあくまで静的な情報であり、実行時に強制されるものではない。
そのため、開発者が型ヒントを更新し忘れた場合や、仕様変更に対して型定義の修正が追いつかなかった場合、型と実際の動作が一致しない状況が発生する。
この状態はコードの信頼性を低下させる要因となる。
例えば、関数の戻り値の型を変更したにもかかわらず、型ヒントを更新しなかった場合、静的解析ツールは誤った前提に基づいて解析を行うことになる。
このような乖離があると、ツールの出力結果が実際の挙動と一致せず、かえって誤解を招く可能性がある。
つまり、型ヒントが「正しい情報である」という前提自体が崩れることになる。
この問題は特に大規模なプロジェクトにおいて顕著になる。
コードベースが大きくなるほど、型ヒントが記述されている箇所も増加し、それらすべてを正確に維持することは容易ではない。
開発チームの人数が多い場合、それぞれの開発者が同じ水準で型定義を更新し続けることは現実的に難しい。
さらに、型ヒントと実装の乖離は、リファクタリングの障害となることもある。
コードの一部を変更した際、関連する型定義をすべて追従して更新する必要があるが、この作業は非常に煩雑であり、変更漏れが発生しやすい。
このような状況では、型ヒントがむしろ開発の負担となり、柔軟な変更を妨げる要因になり得る。
また、型ヒントはあくまで静的解析のための情報であるため、実行時の安全性を直接保証するものではない。
この点において、型ヒントは「見かけ上の正しさ」を提供するに過ぎず、実際の挙動との整合性は別途検証する必要がある。
結果として、型ヒントを導入しても完全な信頼性が得られるわけではない。
この問題に対して、静的型付け言語であればコンパイラが型の整合性を強制するため、型と実装の乖離は原理的に発生しにくい。
しかし、Pythonの型ヒントはこのような強制力を持たないため、開発者自身が責任を持って整合性を維持する必要がある。
この点が、設計思想としての大きな違いである。
一方で、型ヒントと静的解析ツールを組み合わせることで、この乖離をある程度検出することは可能である。
例えば、mypyのようなツールは、型ヒントに基づいてコードを解析し、不整合を警告として提示する。
しかし、この仕組みも万能ではなく、型定義そのものが誤っていれば、その誤りを正しく検出することはできない。
つまり、型ヒントはあくまで「補助的な正しさの仮定」を提供するものであり、それ自体が正しさを保証するものではない。
この前提を理解せずに運用すると、型ヒントに過度に依存し、結果として誤った設計判断を下すリスクがある。
このように、型ヒントと実装の乖離リスクは、単なる技術的な問題ではなく、設計と運用の両面に関わる重要な課題である。
型定義を維持し続けるコストと、それによって得られる安全性のバランスをどう取るかは、プロジェクトごとに慎重に判断すべきである。
結論として、型ヒントは有用な仕組みである一方で、その管理には明確なコストとリスクが伴う。
特に型と実装の乖離という問題は、見過ごされがちでありながら本質的な課題である。
このリスクを考慮すると、型ヒントをあえて導入しない、あるいは最小限に抑えるという選択も、十分に合理的な判断であると言える。
型ヒント不要論を支える開発スタイルと思想
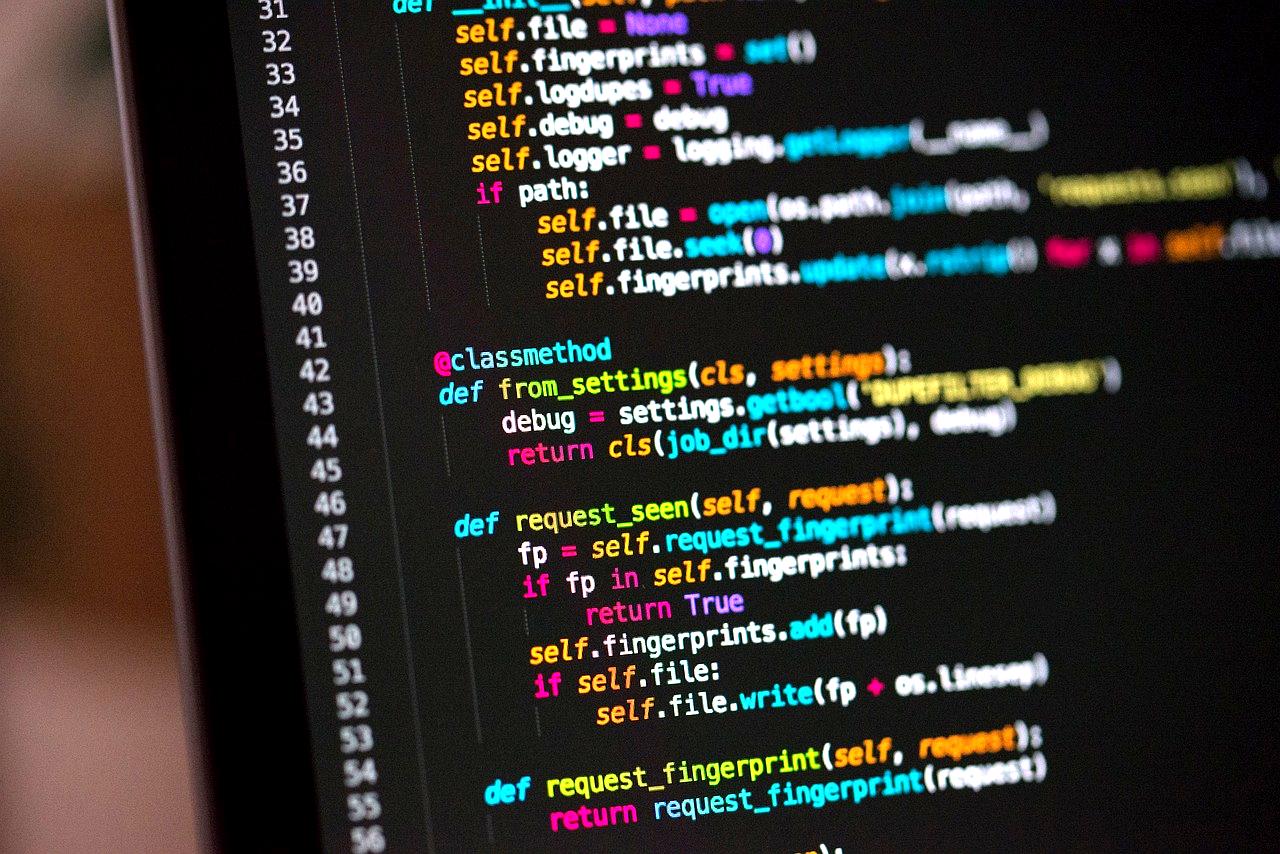
Pythonにおける型ヒント不要論は、単なる好みの問題ではなく、開発スタイルと設計思想に深く根ざした合理的な主張である。
特に、Pythonが持つ哲学的背景を理解すると、型ヒントをあえて使わないという選択が一定の合理性を持つことが見えてくる。
Pythonは「明示は必要だが、過剰な制約は避ける」という思想に基づいて設計されている。
この言語の設計者であるGuido van Rossumの思想は、コードの可読性とシンプルさを最優先する点に特徴がある。
この観点から見ると、型ヒントは有用ではあるものの、必須ではない補助的な機能に過ぎない。
型ヒント不要論を支える開発スタイルの一つに、スクリプト志向のプログラミングがある。
このスタイルでは、短期間で動作するコードを素早く書き上げることが重視される。
こうした場面では、厳密な型定義を行うよりも、柔軟に試行錯誤を繰り返す方が効率的である。
型ヒントを省略することで、コードの記述量を減らし、思考から実装までの距離を短縮できる。
また、Pythonはデータサイエンスや機械学習の分野でも広く利用されているが、これらの領域では特に柔軟性が重要視される。
データの形状や内容は頻繁に変化するため、厳密な型定義が足かせになる場合がある。
このような環境では、型ヒントを最小限に抑えることで、実験的なコードを迅速に書くことが可能になる。
さらに、Pythonの開発においては「明示的であること」と「冗長であること」は必ずしも同義ではない。
型ヒントは明示性を高める一方で、コードの冗長性を増加させる傾向がある。
この点において、シンプルさを重視する開発者にとっては、型ヒントは必ずしも最適な選択ではない。
思想的な側面として重要なのは、「コードは書かれるよりも読まれる回数の方が多い」という原則である。
これは多くのプログラミング言語に共通する考え方であるが、Pythonは特にこの点を重視している。
型ヒントは一見すると可読性を向上させるように見えるが、過度に複雑な型定義はかえって理解を妨げる可能性がある。
特に高度なジェネリクスやネストされた型を使用した場合、その解釈には一定の学習コストが必要となる。
このような背景から、型ヒントを積極的に使わない開発スタイルは、「意図の明確さ」を別の方法で担保しようとするアプローチとも言える。
具体的には、関数の命名やドキュメンテーション、適切な抽象化によって、型情報に依存しない形でコードの意味を伝える設計が行われる。
このアプローチは、型に頼らずに設計の意図を伝えるという点で、より本質的な可読性の追求であると捉えることができる。
また、型ヒント不要論は、過度なツール依存を避けるという思想とも関連している。
型ヒントを活用するためには、mypyのような静的解析ツールや、型対応のIDEが前提となる場合が多い。
これに対して、型ヒントを使用しない開発では、特定のツールに依存せず、シンプルな実行環境だけでコードを扱うことができる。
この点は、環境の制約がある場面や、軽量な開発環境を重視する場合において重要な利点となる。
このように、型ヒント不要論は単なる技術的な議論ではなく、開発哲学や設計思想に深く関わる問題である。
柔軟性、シンプルさ、実験性を重視する開発スタイルにおいては、型ヒントをあえて排除することが合理的な選択となる場合がある。
結論として、型ヒントの採用は一律に決定されるべきものではなく、プロジェクトの目的や開発スタイルに応じて選択されるべきである。
型ヒント不要論を理解することは、Pythonの設計思想をより深く理解することにもつながり、その上で最適な開発方針を選択するための重要な判断材料となる。
VSCodeやPyCharmで見る型ヒントの実用性と開発効率
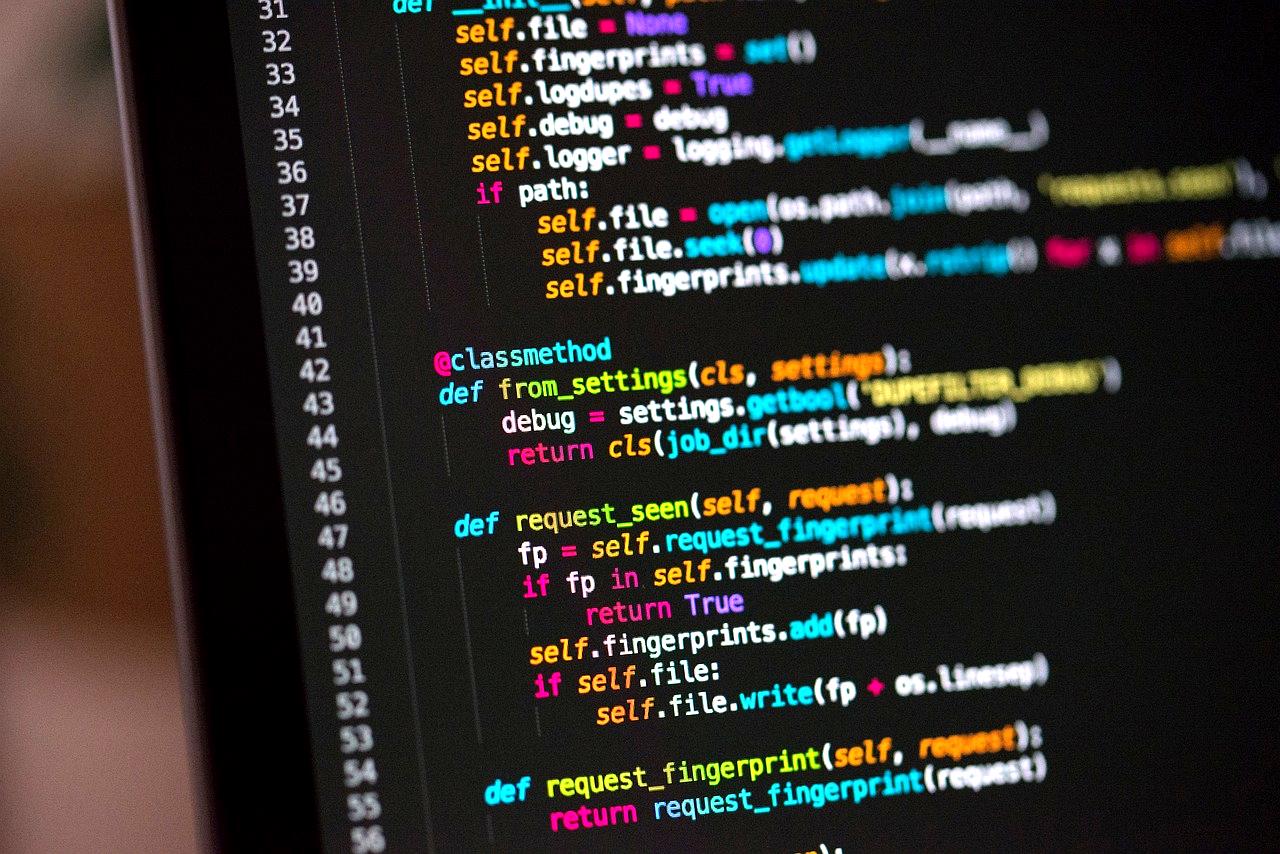
Pythonにおける型ヒントは、単なるコード注釈にとどまらず、IDEとの連携によって実用的な価値を発揮する。
特にVSCodeやPyCharmといった統合開発環境においては、型ヒントを活用することで開発効率が大きく向上する。
ここでは、その具体的な実用性と開発効率への影響について論理的に整理する。
まず、型ヒントの最も分かりやすい恩恵は補完機能の精度向上である。
IDEは型ヒントをもとに変数や関数の型を推論し、適切な候補を提示する。
この機能により、開発者は関数名やメソッド名を完全に覚えていなくても、効率的にコードを書くことができる。
これは特に、ライブラリやフレームワークのAPIを利用する際に大きな効果を発揮する。
次に、エラー検出の早期化という点が挙げられる。
型ヒントを正しく記述しておくことで、IDEは型の不整合をリアルタイムで検出できる。
例えば、整数を期待する関数に文字列を渡してしまった場合、その場で警告が表示される。
このようなフィードバックは、実行前に問題を特定できるという点で、デバッグコストの削減に直結する重要な要素である。
さらに、リファクタリングの安全性も向上する。
IDEは型情報を利用して、コード全体の依存関係を把握することができる。
そのため、関数の引数や戻り値の型を変更した場合でも、影響範囲を正確に特定し、必要な修正箇所を提示することが可能となる。
この機能は、大規模なコードベースにおいて特に重要であり、変更に伴うリスクを大幅に低減する。
VSCodeにおいては、Pylanceなどの言語サーバーが型ヒントを活用して高度な解析を行う。
一方、PyCharmはもともとPythonに特化したIDEであり、型ヒントとの統合が非常に深い。
これらのツールは、単なる補完にとどまらず、コードの構造理解や静的解析を行うことで、開発者の認知負荷を軽減している。
また、型ヒントはチーム開発におけるコミュニケーションツールとしても機能する。
コードを読む開発者は、関数のシグネチャを見るだけで、その関数がどのような入力を受け取り、どのような出力を返すのかを理解できる。
これはドキュメントに頼らずともコードの意図を共有できるという点で、開発効率の向上に寄与する。
ただし、型ヒントの恩恵を最大限に活用するためには、一定の前提条件が存在する。
それは、型情報が正確かつ一貫して記述されていることである。
型ヒントが不正確であったり、部分的にしか記述されていなかったりすると、IDEの解析精度は低下する。
このため、型ヒントは適切に管理されて初めて価値を発揮する。
この点を踏まえると、型ヒントの導入は単なる技術的な選択ではなく、開発プロセス全体に関わる意思決定であると言える。
例えば、静的解析を重視するプロジェクトでは型ヒントは必須に近い存在となるが、スクリプト中心の開発では必ずしも必要ではない。
このように、開発スタイルによって最適な使い方は異なる。
結論として、VSCodeやPyCharmといった現代的なIDEにおいて、型ヒントは単なる補助機能ではなく、開発効率を大きく左右する重要な要素である。
補完精度の向上、エラー検出の早期化、リファクタリングの安全性向上といった複数の観点から、その実用性は非常に高い。
ただし、その価値は正しく運用されてこそ発揮されるものであり、適切な設計と一貫性のある型定義が前提となる点を忘れてはならない。
型ヒントとmypyの活用で変わるPython開発の品質
Pythonにおける型ヒントは、それ単体では実行時の挙動に影響を与えない補助的な仕組みである。
しかし、静的型チェッカーであるmypyと組み合わせることで、その価値は大きく変化する。
特に開発の品質という観点において、型ヒントとmypyの組み合わせは、従来の動的型付けの枠組みに新たな検証レイヤーを追加する役割を果たす。
mypyは、型ヒントを解析し、コード全体の型の整合性を静的に検査するツールである。
これにより、実行前の段階で型に関する潜在的なエラーを検出することが可能になる。
例えば、ある関数が整数を期待しているにもかかわらず、文字列が渡されている場合、mypyはその不整合を警告として報告する。
この仕組みは、従来であれば実行時に初めて発見されていたエラーを、開発段階で事前に把握できる点で非常に重要である。
このような静的検査の導入により、ソフトウェアの信頼性は大きく向上する。
特に、コードベースが大規模化するほど、型に起因するバグの影響範囲は広がるため、早期検出の価値は増していく。
mypyを活用することで、こうしたリスクを体系的に低減することができる。
さらに、mypyは開発プロセスそのものにも影響を与える。
型ヒントを前提とした設計を行うことで、関数やモジュールのインターフェースが明確になり、コードの責務が整理されやすくなる。
これは結果として、より保守性の高いアーキテクチャの構築につながる。
型情報が明示されていることで、コードの利用者はその仕様を直感的に理解できるため、ドキュメントに依存する度合いも減少する。
また、リファクタリングの安全性という観点でもmypyは有効である。
コードの一部を変更した際、型の不整合が発生するとmypyがそれを検出するため、変更による副作用を早期に把握できる。
この特性は、特に長期的に運用されるプロジェクトにおいて重要であり、変更に対する信頼性を高める要因となる。
ただし、mypyの導入は単純なメリットだけをもたらすわけではない。
型ヒントの記述が不十分であったり、誤った型定義が行われていたりすると、mypyの検査結果も正確性を欠くことになる。
このため、型ヒントは「正しく書かれていること」が前提条件となる。
この点は、動的型付けの柔軟性と引き換えに追加される責任であると言える。
さらに、mypyの厳格さは開発の初期段階では負担になる場合もある。
試行錯誤を繰り返しながら設計を固めるフェーズにおいては、型エラーが頻繁に発生し、それらの修正に時間を取られることがある。
このような状況では、型ヒントとmypyの厳密な適用が開発スピードを低下させる可能性がある。
しかし、開発が安定フェーズに入ると、その効果は逆転する。
コードの品質が一定以上に保たれ、予期しない型エラーの発生が抑制されることで、バグ修正やデバッグにかかるコストが削減される。
つまり、型ヒントとmypyは、開発の成熟度に応じて価値が増していくツールである。
また、チーム開発においては、mypyをCI/CDパイプラインに組み込むことで、全てのコミットに対して型チェックを自動的に実行することができる。
この仕組みにより、型の整合性が常に維持され、コードの品質を継続的に監視する体制が構築される。
結論として、型ヒントとmypyの組み合わせは、Pythonにおける動的型付けの柔軟性を維持しながら、静的型付けに近い品質保証を実現する強力な手段である。
その効果は単なるエラー検出にとどまらず、設計の明確化やチーム開発の効率化にも波及する。
したがって、適切に運用される限りにおいて、この組み合わせはPython開発の品質を大きく向上させる重要な要素であると言える。
まとめ:Pythonにおける型ヒントの必要性を再考する
ここまで、Pythonにおける型ヒントの役割と、その不要論が成立する合理的な理由について多角的に検討してきた。
型ヒントは確かに、可読性の向上や静的解析の補助といった明確な利点を持つ一方で、それが常に最適な選択であるとは限らない。
この点を踏まえると、型ヒントの必要性は一律に語れるものではなく、プロジェクトの性質や開発スタイルに強く依存する可変的な要素であると理解するのが適切である。
Pythonは動的型付け言語として設計されており、その柔軟性こそが大きな特徴である。
この柔軟性は、迅速なプロトタイピングやデータ処理、スクリプト開発といった領域において特に強みを発揮する。
型ヒントはその上に後付けされた仕組みであり、本質的な言語の振る舞いを変えるものではない。
この構造を理解することが、型ヒントをどう扱うかを判断する上での前提となる。
一方で、型ヒントを適切に活用することで、開発効率や品質は確実に向上する。
特にIDEとの連携や静的解析ツールとの組み合わせによって、補完機能の強化やエラーの早期検出といった恩恵を受けることができる。
これは、単なる補助的機能にとどまらず、開発体験そのものを改善する要素であると言える。
しかし、その利点はすべての状況において等しく重要であるとは限らない。
例えば、小規模なスクリプトや一時的なツールの開発においては、型ヒントの導入コストがメリットを上回る場合がある。
また、型ヒントの維持には一定のコストが伴い、型と実装の乖離や記述の冗長化といった課題も存在する。
これらの要素は、無視できない実務的な制約である。
重要なのは、型ヒントを「使うか使わないか」という二択で捉えるのではなく、「どの程度使うか」「どの領域で使うか」という粒度で判断することである。
現代のPython開発においては、型ヒントを部分的に導入し、重要なインターフェースや複雑なロジックに限定して適用するというハイブリッドなアプローチが現実的な選択となることが多い。
また、開発チームの成熟度や規模も判断基準として重要である。
大規模なプロジェクトや長期運用が前提となるシステムでは、型ヒントと静的解析ツールを組み合わせることで、保守性と信頼性を高める効果が期待できる。
一方で、個人開発や初期段階のプロジェクトでは、柔軟性を優先し、型ヒントを最小限に抑える判断も合理的である。
結論として、Pythonにおける型ヒントは必須の要素ではなく、あくまで選択可能なツールの一つである。
その価値は文脈依存であり、開発者は自らの目的と制約に応じて適切に判断する必要がある。
型ヒントの導入は目的ではなく手段であり、その本質的な価値は「より良いコードを書くためにどのように活用するか」にある。
最終的には、型ヒントの有無ではなく、コードの品質、可読性、保守性といった本質的な指標に目を向けることが重要である。
Pythonという言語の柔軟性を活かしつつ、必要に応じて型ヒントを取り入れるというバランス感覚こそが、現代的なPython開発において求められる姿勢であると言える。


コメント